Classic five-stage pipeline, RISC-V five-stage pipeline
In CPU design, pipeline design is often used. Compared with the early state machine logic, pipeline design can effectively improve the efficiency of CPU.
Related reference articles:
RISC-V teaching plan
Using the pipeline design will improve the efficiency of the CPU under the existing production process and the same main frequency of the system, usually, we will use MIPS and MIPS/Mhz and other standards to measure.
Among them, MIPS refers to a million instructions per second, which means how many million instructions per second. For example, 5MIPS refers to 5 million instructions per second. This is an absolute value and depends on the effectiveness of the pipeline design, branch prediction, CPU frequency, and so on.
MIPS/Mhz indicates how many MIPS the CPU can execute per 1MHz system clock. For example, 10MIPS/MHz means that if the CPU runs at a frequency of 1MHz, it can execute 10 million instructions per second, and if the CPU runs at a frequency of 5MHz, it can execute 50 million instructions per second. This parameter excludes the parameters of the system clock, so it has nothing to do with the production process and is used to evaluate the design performance of the CPU, not the production process performance.
The more stages in the pipeline, the less logic in each stage of the pipeline, and the higher the main frequency of the clock during production. The disadvantage is: that the more pipeline stages, the more CPU design resources are required, the more complex the CPU design, the higher the cost of handling pipeline conflicts, and the higher the relative power consumption. Therefore, how many stages of the pipeline the CPU is designed is determined by the definition (positioning) of the product.
For some low-power, handheld, or mobile devices, the CPU design expects a long standby time and low product power consumption, and performance is not a priority. This reduces the number of pipeline stages and can even use a state machine instead. For high-performance devices, performance is the first priority, then power consumption, then the number of pipeline stages will be increased accordingly, resulting in a higher frequency.
State machine logic :
Example:
The machine code corresponding to ADDI x13, x12, 5 is 0000_0000_0101_01100_000_01101_0010011, and the corresponding hexadecimal is 32’h0056_0693
 Figure 3 ADDI machine code format [2]
Figure 3 ADDI machine code format [2]

Pipeline logic:
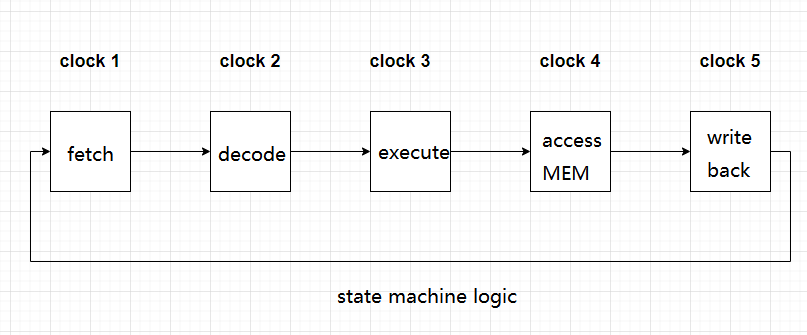
In the classic pipeline design, the 5-stage pipeline is very representative. It mainly includes:
1) Fetch IF, (instruction fetch)
2) Decoding ID, (instruction decoder)
3) Execute EX, (execution )
4) Access MEM, (access memory)
5) Write back to WB (write back)
Consists of 5 parts (5 levels).

cycle 1 : The fetch of the first instruction.
cycle 2: Decoding of the first instruction, fetching of the second instruction.
cycle 3: The execution of the first instruction, the decoding of the second instruction, and the fetch of the third instruction.
cycle 4: The 1st instruction is fetched, the 2nd instruction is executed, the 3rd instruction is decoded, and the 4th instruction is fetched.
cycle 5: write-back of the 1st instruction, fetch the 2nd instruction, execute the 3rd instruction, decode the 4th instruction, and fetch the 5th instruction.
cycle 6: The 6th instruction is fetched, the 2nd instruction is written back, the 3rd instruction is fetched, the 4th instruction is executed, and the 5th instruction is decoded.
cycle 7: Decode the 6th instruction , fetch the 7th instruction , write the 3rd instruction back , decode the 4th instruction , and execute the 5th instruction .
cycle 8: Execution of the 6th instruction, decoding of the 7th instruction, fetching of the 8th instruction, execution of the 4th instruction, and memory fetching of the 5th instruction.
cycle 9: The 6th instruction is fetched, the 7th instruction is executed, the 8th instruction is decoded, the 9th instruction is fetched, and the 5th instruction is written back.
It can be seen that in the first clock cycle, only 1 instruction operation is executed; in the second clock cycle, 2 instruction operations are executed; in the third clock cycle, 3 instruction operations are executed;
In the fourth clock cycle, 4 instruction operations are executed; starting from the fifth clock, 5 instruction operations are executed in each clock cycle. This is equivalent to each subsequent clock cycle, a complete instruction is executed (instruction fetch, decode, execute, fetch, write back). This is where the efficiency of the CPU reaches its highest value (ideal state). When the CPU executes instructions, it will encounter jumps, branch jumps, long-cycle instructions (multiplication, division), and long-cycle memory access (flash, DDR, etc.), the pipeline will be suspended, and even exit and restart. In order to reduce the occurrence of pauses and exits, various CPUs have corresponding means to avoid them as much as possible.
RISC-V 5-stage pipeline design :
RISC-v also has a classic 5-level pipeline design, but also has 2-level, 3-level, 7-level, and even more pipeline designs, depending on the company’s definition of the product, RISC-V itself does not stipulate how many stages must be used. .

First-level fetch:

The instruction fetch is mainly to control the pc (program counter). In general, each clock cycle pc = pc + 4; at the same time, the instruction is sent to the decoding module; but if there are BRANCH, JAL, JALR, AUIPC, the pc will be modified to these instructions Calculated value, and take the calculated pc as the address, read the instruction of the corresponding address, and send it to the decoding module.
Second level decoding:

The decoding module is responsible for separating out the instructions:
1) What is the specific instruction (ADDI, AND, JAL, LUI, etc.),
2) Which registers are required to cooperate with the execution of the next level (rs1, rs2, rd)
3) Load/save etc. need the address of the memory (get the data in the address)
The third level of execution:

According to the decoding result, perform corresponding calculations: including add, xor, or, and, pc jump, branch jump and so on. In a variable-stage pipeline (not a fixed 5-stage pipeline design) can also be based on instructions
Write back directly.
Fourth level fetch:

Operations such as load, store, etc. access memory, or access to csr registers.
Episode 5 write-back:

The final result is written back to 32 general-purpose registers to complete the operation of the instruction cycle.
The pipeline can be designed as 2-stage, 3-stage, 5-stage, and more. But it can also be designed as a variable-stage pipeline. According to different instructions, the operation of the entire instruction can be quickly completed, thereby speeding up the execution speed of the CPU.
For example, add x2, x3, x4 has no memory access. After execution, it can be written back directly.
